Functions:
| Name | Description |
|---|---|
evaluation | 단일 image 내 detection model의 추론 성능 평가 |
iou | IoU (Intersection over Union)를 계산하는 function |
meanap | Detection model의 P-R curve 시각화 및 mAP 산출 |
_append(logs: dict[str, list[Any]], instance: int, confidence: float, class_: int | str, iou_: float, results: str, gt: NDArray[DTypeLike] | None, inf: NDArray[DTypeLike] | None) -> None
Source code in zerohertzLib/vision/eval.py
Source code in zerohertzLib/vision/eval.py
_prc_curve(confidence_per_cls: dict[str, list[float]], recall_per_cls: dict[str, list[float]], precision_per_cls: dict[str, list[float]], classes: set[str]) -> None
Source code in zerohertzLib/vision/eval.py
evaluation(ground_truths: NDArray[DTypeLike], inferences: NDArray[DTypeLike], confidences: list[float], gt_classes: list[str] | None = None, inf_classes: list[str] | None = None, file_name: str | None = None, threshold: float = 0.5) -> DataFrame
단일 image 내 detection model의 추론 성능 평가
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
ground_truths | NDArray[DTypeLike] | Ground truth object들의 polygon ( | required |
inferences | NDArray[DTypeLike] | Model이 추론한 각 object들의 polygon ( | required |
confidences | list[float] | Model이 추론한 각 object들의 confidence( | required |
gt_classes | list[str] | None | Ground truth object들의 class ( | None |
inf_classes | list[str] | None | Model이 추론한 각 object들의 class ( | None |
file_name | str | None | 평가 image의 이름 | None |
threshold | float | IoU의 threshold | 0.5 |
Note
N: 한 image의 ground truth 내 존재하는 object의 수M: 한 image의 inference 결과 내 존재하는 object의 수
Returns:
| Type | Description |
|---|---|
DataFrame | 단일 image의 model 성능 평가 결과 |
Examples:
>>> poly = np.array([[0, 0], [10, 0], [10, 10], [0, 10]])
>>> ground_truths = np.array([poly, poly + 20, poly + 40])
>>> inferences = np.array([poly, poly + 19, poly + 80])
>>> confidences = np.array([0.6, 0.7, 0.8])
>>> zz.vision.evaluation(ground_truths, inferences, confidences, file_name="test.png")
file_name instance confidence class IoU results gt_x0 gt_y0 gt_x1 gt_y1 gt_x2 gt_y2 gt_x3 gt_y3 inf_x0 inf_y0 inf_x1 inf_y1 inf_x2 inf_y2 inf_x3 inf_y3
0 test.png 0 0.8 0.0 0.000000 FP NaN NaN NaN NaN NaN NaN NaN NaN 80.0 80.0 90.0 80.0 90.0 90.0 80.0 90.0
1 test.png 1 0.7 0.0 0.680672 TP 20.0 20.0 30.0 20.0 30.0 30.0 20.0 30.0 19.0 19.0 29.0 19.0 29.0 29.0 19.0 29.0
2 test.png 2 0.6 0.0 1.000000 TP 0.0 0.0 10.0 0.0 10.0 10.0 0.0 10.0 0.0 0.0 10.0 0.0 10.0 10.0 0.0 10.0
3 test.png 3 0.0 0.0 0.000000 FN 40.0 40.0 50.0 40.0 50.0 50.0 40.0 50.0 NaN NaN NaN NaN NaN NaN NaN NaN
>>> gt_classes = np.array(["cat", "dog", "cat"])
>>> inf_classes = np.array(["cat", "dog", "cat"])
>>> zz.vision.evaluation(ground_truths, inferences, confidences, gt_classes, inf_classes)
instance confidence class IoU results gt_x0 gt_y0 gt_x1 gt_y1 gt_x2 gt_y2 gt_x3 gt_y3 inf_x0 inf_y0 inf_x1 inf_y1 inf_x2 inf_y2 inf_x3 inf_y3
0 0 0.8 cat 0.000000 FP NaN NaN NaN NaN NaN NaN NaN NaN 80.0 80.0 90.0 80.0 90.0 90.0 80.0 90.0
1 1 0.6 cat 1.000000 TP 0.0 0.0 10.0 0.0 10.0 10.0 0.0 10.0 0.0 0.0 10.0 0.0 10.0 10.0 0.0 10.0
2 2 0.0 cat 0.000000 FN 40.0 40.0 50.0 40.0 50.0 50.0 40.0 50.0 NaN NaN NaN NaN NaN NaN NaN NaN
3 3 0.7 dog 0.680672 TP 20.0 20.0 30.0 20.0 30.0 30.0 20.0 30.0 19.0 19.0 29.0 19.0 29.0 29.0 19.0 29.0
Source code in zerohertzLib/vision/eval.py
95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 | |
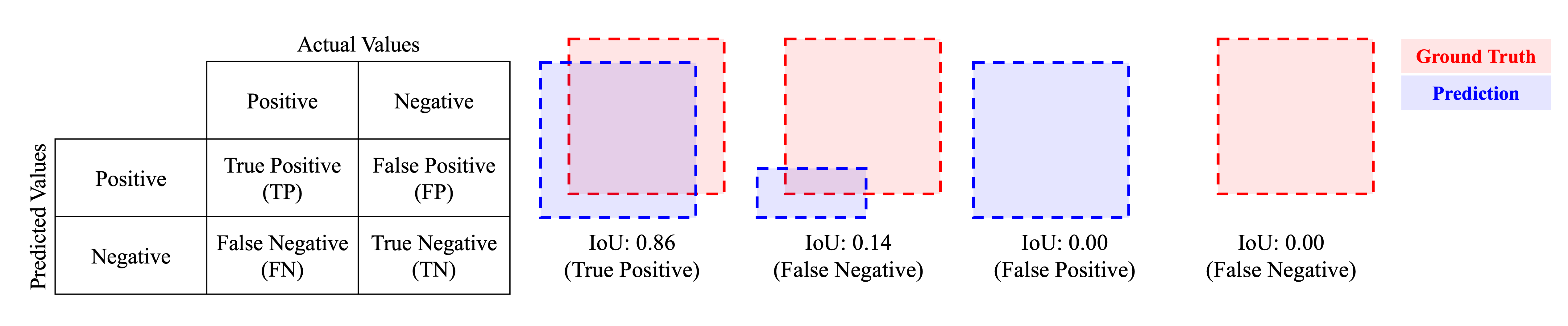
IoU (Intersection over Union)를 계산하는 function
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
poly1 | NDArray[DTypeLike] | IoU를 계산할 polygon ( | required |
poly2 | NDArray[DTypeLike] | IoU를 계산할 polygon ( | required |
Returns:
| Type | Description |
|---|---|
float | IoU 값 |
Examples:
>>> poly1 = np.array([[0, 0], [10, 0], [10, 10], [0, 10]])
>>> poly2 = poly1 + (5, 0)
>>> poly2
array([[ 5, 0],
[15, 0],
[15, 10],
[ 5, 10]])
>>> zz.vision.iou(poly1, poly2)
0.3333333333333333
Source code in zerohertzLib/vision/eval.py
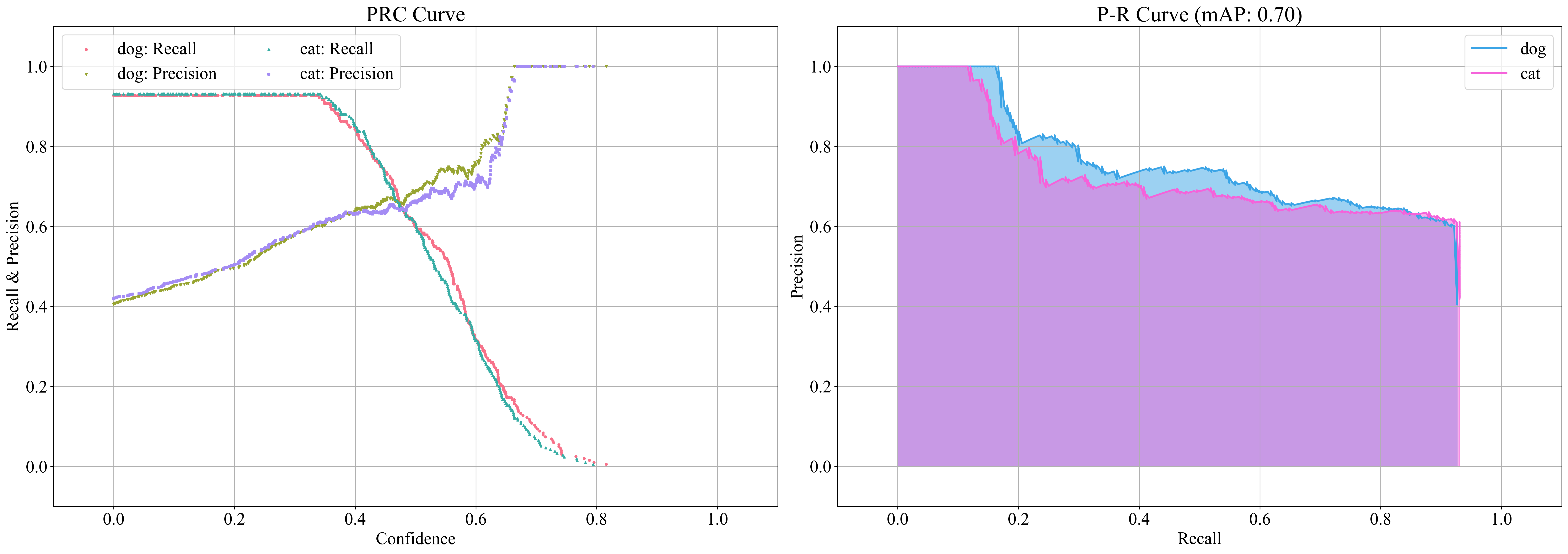
Detection model의 P-R curve 시각화 및 mAP 산출
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
logs | DataFrame |
| required |
Returns:
| Type | Description |
|---|---|
tuple[float, dict[str, float]] | mAP 값 및 class에 따른 AP 값 (시각화 결과는 |
Examples:
>>> logs1 = zz.vision.evaluation(ground_truths_1, inferences_1, confidences_1, gt_classes, inf_classes, file_name="test_1.png")
>>> logs2 = zz.vision.evaluation(ground_truths_2, inferences_2, confidences_2, gt_classes, inf_classes, file_name="test_2.png")
>>> logs = pd.concat([logs1, logs2], ignore_index=True)
>>> zz.vision.meanap(logs)
(0.7030629916206652, defaultdict(<class 'float'>, {'dog': 0.7177078883735305, 'cat': 0.6884180948677999}))