MLOps
MLOps에서 사용되는 class들
Modules:
| Name | Description |
|---|---|
cli | |
client | |
server | |
Classes:
| Name | Description |
|---|---|
BaseTritonPythonModel | Triton Inference Server에서 Python backend 사용을 위한 class |
TritonClientK8s | Kubernetes에서 실행되는 triton inference server의 호출을 위한 class |
TritonClientURL | 외부에서 실행되는 triton inference server의 호출을 위한 class |
module-attribute ¶
Bases: ABC
Triton Inference Server에서 Python backend 사용을 위한 class
Note
Abstract Base Class: Model의 추론을 수행하는 abstract method _inference 정의 후 사용
Examples:
model.py:
class TritonPythonModel(zz.mlops.BaseTritonPythonModel):
def initialize(self, args: dict[str, str]) -> None:
super().initialize(args)
self.model = Model(cfg)
def _inference(input) -> tuple[Any]:
return self.model(input)
Normal Logs (Without Batching):
2025-09-25 16:06:51.904 | INFO | zerohertzLib.mlops.triton:initialize:* - Initialize: {
"name": "...",
"platform": "",
"backend": "python",
"runtime": "",
"version_policy": {
"latest": {
"num_versions": 1
}
},
"max_batch_size": 0,
...
2025-09-25 16:22:48.226 | INFO | zerohertzLib.mlops.triton:execute:* - Called
2025-09-25 16:22:48.234 | DEBUG | zerohertzLib.mlops.triton:_get_inputs:* - inputs: images=(2078, 1470, 3)
2025-09-25 16:22:48.234 | INFO | zerohertzLib.mlops.triton:execute:* - Inference start
2025-09-25 16:22:49.026 | INFO | zerohertzLib.mlops.triton:execute:* - Inference completed (0.79s)
2025-09-25 16:22:49.026 | DEBUG | zerohertzLib.mlops.triton:_set_outputs:* - outputs: boxes=(12, 4), scores=(12,), labels=(12,)
Normal Logs (With Batching):
2025-11-07 08:36:52.242 | INFO | zerohertzLib.mlops.triton:execute:* - Called
2025-11-07 08:36:52.276 | DEBUG | zerohertzLib.mlops.triton:_get_inputs:* - inputs: images=(5, 3000, 3000, 3)
2025-11-07 08:36:52.276 | INFO | zerohertzLib.mlops.triton:execute:* - Inference start
2025-11-07 08:36:54.091 | INFO | zerohertzLib.mlops.triton:execute:* - Inference completed (1.81s)
2025-11-07 08:36:54.092 | DEBUG | zerohertzLib.mlops.triton:_set_outputs:* - outputs (0 ~ 1): bboxes=(235, 4, 2), (293, 4, 2), texts=(235,), (293,), scores=(235,), (293,), batch_index=(235,), (293,)
2025-11-07 08:36:54.092 | DEBUG | zerohertzLib.mlops.triton:_set_outputs:* - outputs (2 ~ 4): bboxes=(293, 4, 2), (46, 4, 2), (235, 4, 2), texts=(293,), (46,), (235,), scores=(293,), (46,), (235,), batch_index=(293,), (46,), (235,)
Error Logs:
2025-09-25 16:26:32.004 | ERROR | zerohertzLib.mlops.triton:execute:* - zerohertzLib!
Traceback (most recent call last):
> File "/usr/local/lib/python3.10/dist-packages/zerohertzLib/mlops/triton.py", line 371, in execute
outputs = self._inference(**inputs)
| | -> {'images': array([[[ 38, 38, 38],
| | [ 37, 37, 37],
| | [ 37, 37, 37],
| | ...,
| | [255, 255, 255],
| | ...
| -> <function TritonPythonModel._inference at 0x7f106f48f400>
-> <1.model.TritonPythonModel object at 0x7f121fa1f010>
File "/models/docling_layout_old_static/1/model.py", line 34, in _inference
raise Exception("zerohertzLib!")
Exception: zerohertzLib!
Methods:
| Name | Description |
|---|---|
execute | Triton Inference Server 호출 시 수행되는 method |
finalize | Triton Inference Server 종료 시 수행되는 method |
initialize | Triton Inference Server 시작 시 수행되는 method |
Source code in zerohertzLib/mlops/server.py
abstractmethod ¶
Source code in zerohertzLib/mlops/server.py
Triton Inference Server 호출 시 수행되는 method
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
requests | list[Any] | Client에서 전송된 model inputs | required |
Returns:
| Type | Description |
|---|---|
list[Any] | Client에 응답할 model의 추론 결과 |
Source code in zerohertzLib/mlops/server.py
Triton Inference Server 시작 시 수행되는 method
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
args | dict[str, str] |
| required |
Source code in zerohertzLib/mlops/server.py
Bases: TritonClientURL
Kubernetes에서 실행되는 triton inference server의 호출을 위한 class
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
svc_name | str | 호출할 triton inference server의 Kubernetes service의 이름 | required |
namespace | str | 호출할 triton inference server의 namespace | required |
port | int | triton inference server의 gRPC 통신 port 번호 | 8001 |
verbose | bool | Verbose 출력 여부 | False |
Examples:
Kubernetes:
$ kubectl get svc -n yolo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
fastapi-svc ClusterIP 10.106.72.126 <none> 80/TCP 90s
triton-inference-server-svc ClusterIP 10.96.28.172 <none> 8001/TCP 90s
$ docker exec -it ${API_CONTAINER} bash
>>> tc = zz.mlops.TritonClientK8s("triton-inference-server-svc", "yolo")
>>> tc("YOLO", np.zeros((1, 3, 640, 640)))
{'output0': array([[[3.90108061e+00, 3.51982164e+00, 7.49971962e+00, ...,
2.21481919e-03, 1.17585063e-03, 1.36753917e-03]]], dtype=float32)}
Source code in zerohertzLib/mlops/client.py
Bases: InferenceServerClient
외부에서 실행되는 triton inference server의 호출을 위한 class
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
url | str | 호출할 triton inference server의 URL | required |
port | int | triton inference server의 gRPC 통신 port 번호 | 8001 |
verbose | bool | Verbose 출력 여부 | False |
Examples:
>>> tc = zz.mlops.TritonClientURL("localhost")
>>> tc("YOLO", np.zeros((1, 3, 640, 640)))
{'output0': array([[[3.90108061e+00, 3.51982164e+00, 7.49971962e+00, ...,
2.21481919e-03, 1.17585063e-03, 1.36753917e-03]]], dtype=float32)}
Methods:
| Name | Description |
|---|---|
__call__ | Model 호출 수행 |
load_model | Triton Inference Server 내 model을 load하는 function |
status | Triton Inferece Server의 상태를 확인하는 function |
unload_model | Triton Inference Server 내 model을 unload하는 function |
Attributes:
| Name | Type | Description |
|---|---|---|
configs | | |
emoji | | |
models | | |
url | |
Source code in zerohertzLib/mlops/client.py
instance-attribute ¶
__call__(model: int | str, *args: list[Any] | NDArray[DTypeLike], renew: bool = False) -> dict[str, NDArray[DTypeLike]]
Model 호출 수행
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model | int | str | 호출할 model의 이름 및 ID | required |
*args | list[Any] | NDArray[DTypeLike] | Model 호출 시 사용될 입력 | () |
renew | bool | 각 모델의 상태 조회 시 갱신 여부 | False |
Returns:
| Type | Description |
|---|---|
dict[str, NDArray[DTypeLike]] | 호출된 model의 결과 |
Source code in zerohertzLib/mlops/client.py
_set_input(input_info: dict[str, list[int]], value: list[Any] | NDArray[DTypeLike], max_batch_size: int | None) -> InferInput
Source code in zerohertzLib/mlops/client.py
load_model(model_name: int | str, headers: str | None = None, config: str | None = None, files: str | None = None, client_timeout: float | None = None) -> None
Triton Inference Server 내 model을 load하는 function
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name | int | str | Load할 model의 이름 또는 ID | required |
headers | str | None | Request 전송 시 포함할 추가 HTTP header | None |
config | str | None | Model load 시 사용될 config | None |
files | str | None | Model load 시 override model directory에서 사용할 file | None |
client_timeout | float | None | 초 단위의 timeout | None |
Examples:
Source code in zerohertzLib/mlops/client.py
Triton Inferece Server의 상태를 확인하는 function
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
renew | bool | 각 모델의 상태 조회 시 갱신 여부 | False |
sortby | str | 정렬 기준 | 'STATE' |
reverse | bool | 정렬 역순 여부 | False |
Examples:
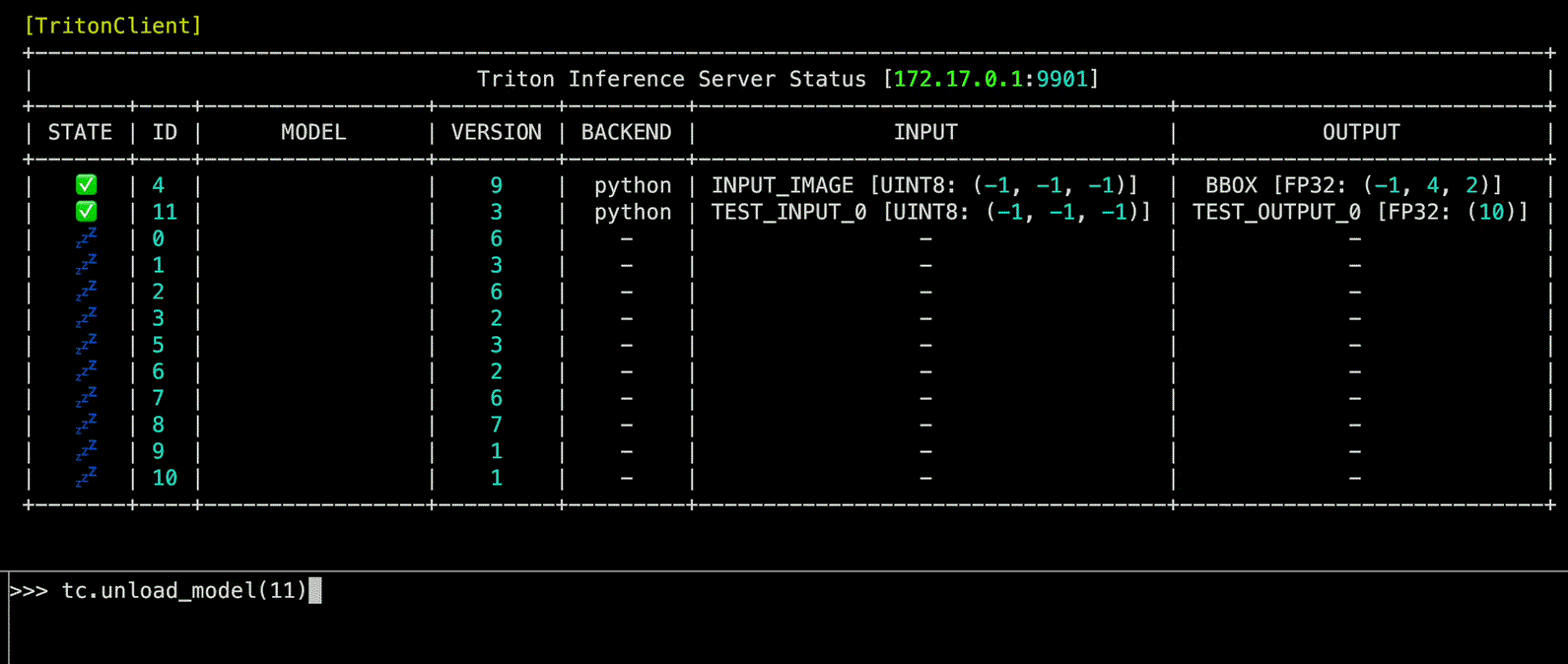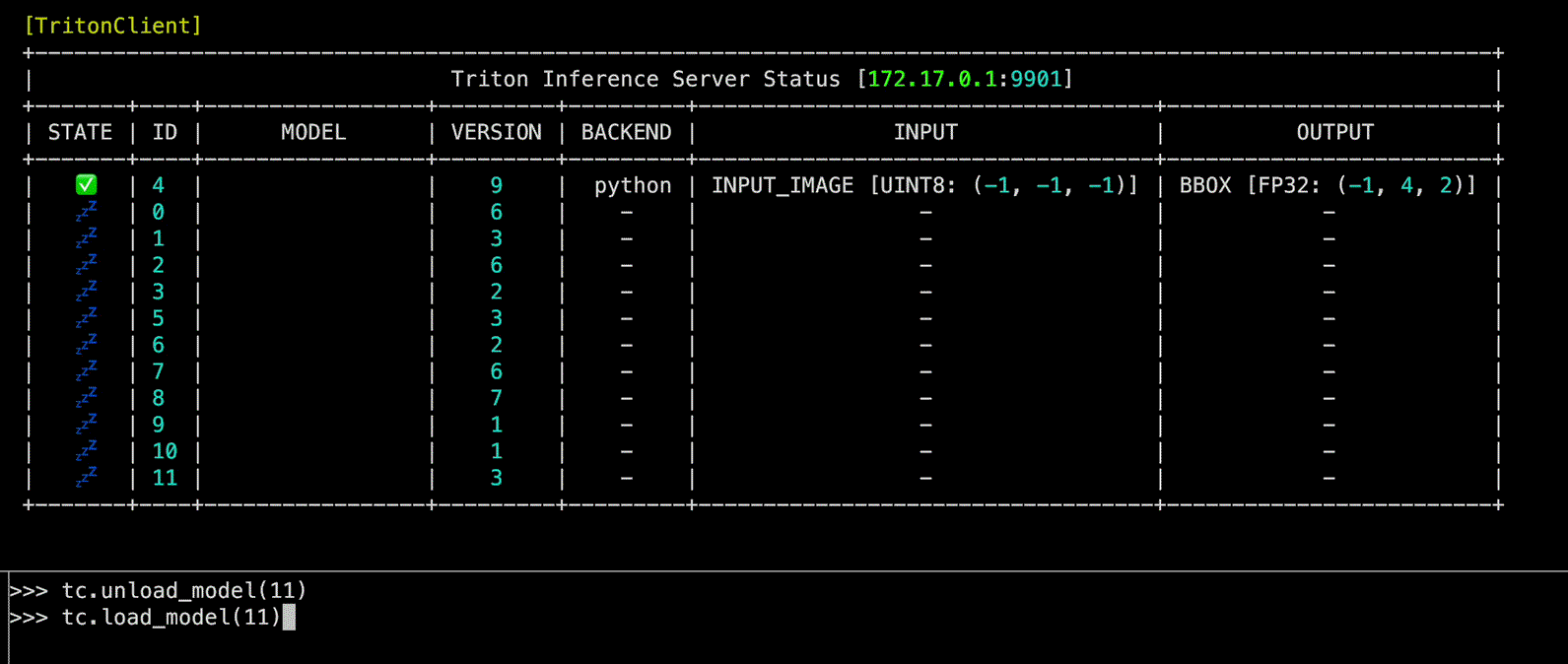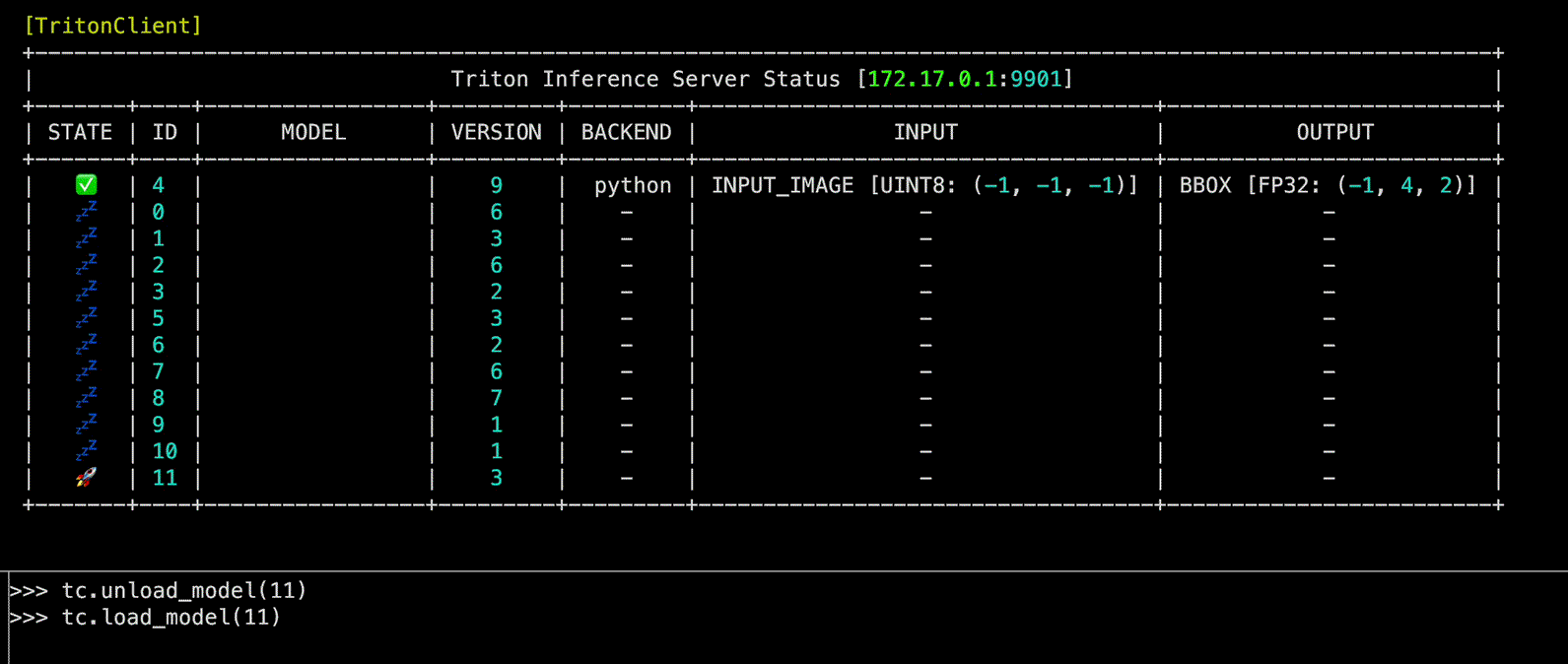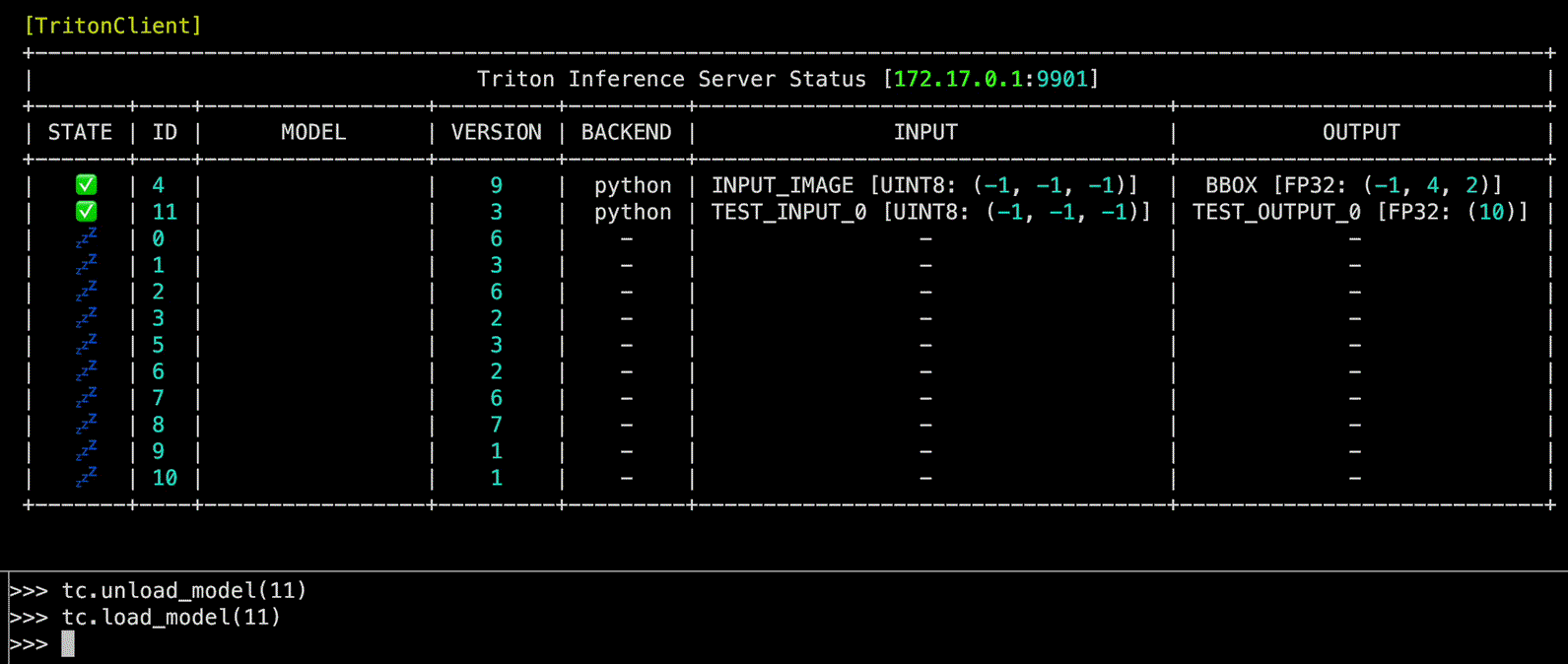
Source code in zerohertzLib/mlops/client.py
unload_model(model_name: int | str, headers: str | None = None, unload_dependents: bool = False, client_timeout: float | None = None) -> None
Triton Inference Server 내 model을 unload하는 function
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name | int | str | Unload할 model의 이름 또는 ID | required |
headers | str | None | Request 전송 시 포함할 추가 HTTP header | None |
unload_dependents | bool | Model unload 시 dependents의 unload 여부 | False |
client_timeout | float | None | 초 단위의 timeout | None |
Examples: